
Week 7 — Dynamic capabilities in the wild: why governments innovate in “disguise”
Dynamic capabilities rarely arrive by name. They arrive as hacks—challenges, labs, sandboxes —because these forms create enough legitimacy to do the work the core organisation can’t safely do.


Illustration by Kadi Estland
Christian Bason once argued that we should stop building labs in isolation and instead make the entire organisation the lab—human, meaningful, creative, caring, collaborative, trusting, thriving. “Tear their existing parent organizations apart, and assemble them from scratch,” he wrote.
It’s an inspiring provocation. But it also immediately runs into a sober empirical reality: many civil servants are (often very justifiably) reluctant to take on the deeper “transition tasks” implied by decarbonisation, ageing, health-system change, or other system transformations. Braams et al. show this reluctance isn’t mere conservatism or risk aversion; it is deeply tied to what public administration recognises as legitimate work—mandates, accountability, risk, and political exposure.
So Week 7 is where our dynamic capabilities lens meets the street. The question is no longer “do we need capabilities?” but: how do dynamic capabilities actually appear in practice—when public servants feel constrained, leadership is stretched, and legitimacy is on the line?
From a neat framework to a messy reality
In Weeks 5–6, we built a simple (but demanding) claim: dynamic capabilities are repeatable organisational abilities that allow public organisations to adapt and transform how they operate under uncertainty—so they can solve everyday problems and emerging challenges.
In the lecture of Week 6, we discussed five such capabilities:
Strategic awareness: noticing emerging needs/risks early and translating them into shared attention and action.
Adjusting priorities: making explicit trade-offs and shifting resources as conditions change.
Building coalitions: convening and governing multi-actor arrangements that add resources, legitimacy, and delivery capacity.
Learning & experimentation: running trials, evaluating, retaining learning, and scaling/stopping based on evidence.
Reconfiguring delivery: redesigning delivery infrastructure—structures, teams, platforms, roles, procurement—so new priorities become executable, repeatedly.
Crucially, each one is observable only when it becomes a repeatable activity—not a one-off hero story. However, that is also why distinguishing routines vs dynamic capabilities is important in this context: routines are the repeated day-to-day patterns; dynamic capabilities are what let you reconfigure those routines when the world shifts or your organisation is not impactful as imagined.
And we can see the impact as a ladder of outcomes:
Short term (~1 year): service-level improvements (access, waiting times, error rates, satisfaction, equity).
Mid term (~5 years): policy-area performance improvements (air quality, homelessness levels, safety outcomes).
Long term (~10 years): system-wide outcomes (population health, resilience, trust/legitimacy, wellbeing).
So far, so tidy.
The hard part: in the wild, dynamic capabilities often don’t look like dynamic capabilities.
Why transition tasks trigger reluctance (and why that matters for capabilities)
Braams et al. give us a very practical entry point: “transition tasks” require public servants to do things that collide with established PA legitimacy routines—especially in administrative traditions shaped by rule-following, procedural accountability, and blame avoidance.
We can map such reluctance across dynamic capabilities as deep-seated constraints driven by interactions of structural capacity (e.g., PA tradition) and everyday routines:
Strategic awareness can be blocked by “no mandate to look beyond remit.”
Adjusting priorities can be blocked by budgeting rules and blame risk.
Coalitions can be blocked by procurement/accountability/legitimacy anxieties.
Experimentation can be blocked by fear of failure and concerns about “randomness” and fairness.
Reconfiguring delivery can be blocked by HR, organisational rigidity, and procurement constraints.
However, this is not a personality flaw that can be cured by market incentives or training programmes; it is often a capability constraint produced by the legitimacy machinery in which organisations and civil servants act.
Which leads to a paradox:
If transition tasks clash with legitimacy routines, then dynamic capabilities will tend to emerge in protective institutional forms—structures that make “doing unusual things” feel legitimate enough to attempt.
This is exactly why we see the explosion of what look like “innovation fashions” across government—labs, missions, challenge prizes, sandboxes, digital agencies, hackathons, purpose-oriented procurement, portfolios, RCTs, experimentalist governance. These aren’t just trend objects; they are often institutional disguises for dynamic capabilities.
Dynamic capabilities in disguise: the protective shells of challenge-driven government
I develop a simple typology of these shells, and it’s worth reading it as a map of where capabilities try to live when the core organisation can’t (yet) host them: foresight units, digital teams, labs, sandboxes, hackathons, technology prizes, challenge prizes, purpose-oriented procurement, missions (summarised below).
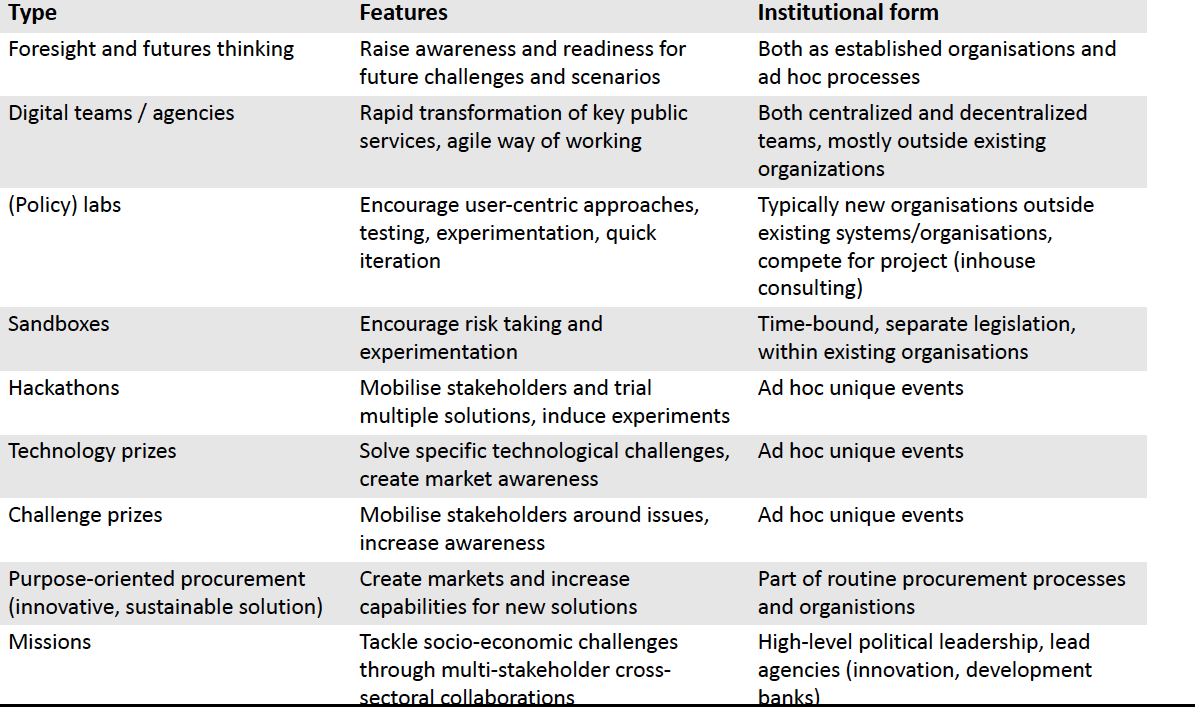
What do these forms have in common?
Strong joint political and managerial leadership
Market-shaping intent (not just fixing failures)
Mixed analytical approaches to identify user needs and bottlenecks
Extensive networking and engagement
Encouraged risk-taking and experimentation
Portfolio logic rather than silver bullets
Conscious building of some new managerial/operational capabilities
In other words, we can see how these different disguises help develop new forms of public leadership — metagovernors from Week 6 — and some organisational new capabilities. But we also see that most of these forms tend be time-bound or outside the machinery of government. Hence, they are not very sticky.
Coming back to Bason, we can say that “whole-of-organisation-as-a-lab” is a destination; protective shells are the bridge.
But they come with a risk: if the shell does not connect back into the organisation’s core routines, you get pilot theatre, innovation islands, and performative experimentation.
So the question becomes organisational (not rhetorical): what makes these shells permeable enough to change the host organisation?
Metagovernance meets delivery
This is where discussions of Week 7 lean heavily on what we discussed in Week 6: public leaders increasingly have to be metagovernors—steering and orchestrating across boundaries—while also being operationally credible in delivery. In other words, political skills and implementation savvy are often distributed across leadership teams.
That’s one reason transition tasks feel risky: they demand cross-system orchestration (politics, narrative, coalition-building, market-shaping), while still being judged by administrative routines designed for a world of stable programmes and bounded remits.
So if reluctance is partially rational, then leadership is partially architectural:
creating mandates that legitimise “looking beyond remit,”
redesigning accountability so experimentation is not instantly blame-able,
building decision points that force scaling/stopping (not endless piloting),
and protecting learning cycles long enough to matter.
Experimentation is not evidence: it’s organisational design under uncertainty
Why has “experimenting” become such a fashionable word in government? Partly because the world has shifted from risk (known probabilities, controllable variation) to uncertainty (unknowns, feedback loops, surprises). Under risk you can optimise; under uncertainty you have to learn your way forward. That’s the deep driver behind the current experimental turn in public administration.
This is also why field experiments have become so attractive. They promise causal insight in real settings: what changes behaviour, what improves uptake, what reduces friction, what actually works on the ground. But public administration isn’t a lab environment, and experiments in PA face recurring constraints that are political and organisational as much as methodological: political sensitivity (who benefits, who loses), ethics (fairness, consent, vulnerability), gatekeepers (who can say yes), spillovers and implementation variance (real life is messy). Hansen & Tummers’ review captures the point neatly: experiments in PA fail or succeed based on governance as much as design.
That is why, in our context, experiments only count as a dynamic capability when they become repeatable machinery: propose → test → learn → scale/stop → institutionalise. Not “we did a pilot,” but “we have a routine that forces decisions and absorbs learning back into rules, services, and budgets.” The practical constraints are predictable: cost and operational burden (permissions, timeline, staff time), ethics (fairness and transparency), and validity (spillovers, compliance, context dependence, measurement). When these constraints aren’t treated as design parameters, experimentation becomes pilot theatre.
There is a second trap as well: deceptive certainty. Evidence can easily become a managerial talisman—used to shut down debate (“the numbers say…”) rather than to organise learning (“what did we misunderstand?”). The lesson isn’t “don’t experiment.” It’s: treat evidence as a learning practice embedded in institutions, not as a decision machine that outputs truth.
So where are experiments most useful? The short answer is: where the organisation is trying to learn how to do things differently, not just whether an intervention has a measurable effect. In practice, that often means using experimental approaches to surface assumptions, reveal bottlenecks, and enable double-loop learning (changing frames and routines), not only single-loop learning (tweaking performance inside an existing model).
At that point, “experimentation” becomes a big umbrella. It includes not only RCTs and behavioural trials, but also experimentalist governance (common goals, multiple pathways, iterative reporting and revision), behavioural units, public design, and innovation portfolios—each with different implications for how legitimacy, authority, and learning are organised.
And that leads to the (deliberately tentative) typology I use in the lecture (see below) —a simple way to see that experimental public administration varies along two dimensions: iterative vs competitive, and instruments vs behavioural change.
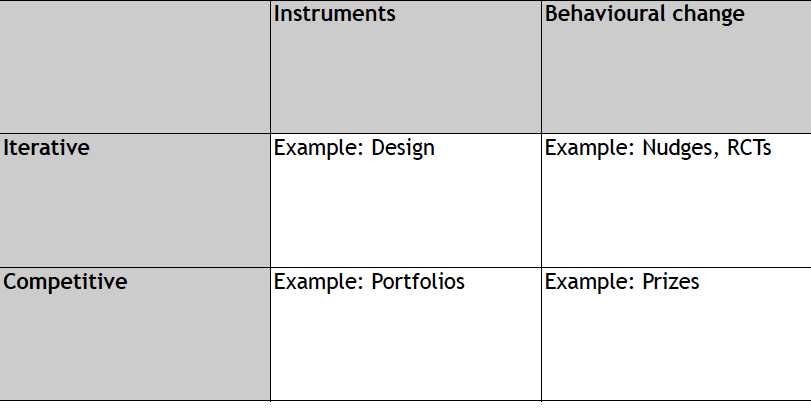
What this typology also clarifies is that the five dynamic capabilities from the lecture express quite differently in each box—and with very different degrees of stickiness. In Design (iterative + instruments), capabilities can become most embedded: strategic awareness is built through continuous user research and feedback loops; learning & experimentation is routine (prototyping, iteration); reconfiguring delivery shows up as redesigned processes, standards, and platforms—so the capability can “live” inside day-to-day routines rather than a special project team. In Nudges/RCTs (iterative + behavioural change), the strongest capability is typically learning & experimentation (clean tests, iteration), with some strategic awareness (diagnosing bottlenecks), but the stickiness depends on whether findings translate into adjusting priorities and reconfiguring delivery—otherwise the evidence sits on top of unchanged operational machinery. In Portfolios (competitive + instruments), dynamic capabilities concentrate in adjusting priorities (resource allocation, sequencing, stop/scale decisions) and building coalitions (aligning partners, mandates, and delivery chains), yet they can remain episodic if portfolio governance happens as a one-off funding moment rather than a standing decision forum with explicit learning and reconfiguration loops. And in Prizes (competitive + behavioural change), capabilities are often the most ad hoc: strong for strategic awareness (surfacing problems/solutions and new actors) and some coalition-building (signalling, convening), but unless prizes are designed as on-ramps into procurement, regulation, or service redesign, they rarely produce durable reconfiguring delivery routines.
Two UBI experiments as capability stress tests: Finland and Kenya
This week’s seminar cases use UBI experiments to show what experimentation in PA is really about: not just testing a policy idea, but stress-testing capacity, routines, and capability-building pathways.
Finland: experimentation inside a high-capacity welfare state
Finland’s basic income experiment (2017–2018) was run by Kela as a statutory, randomised national trial: 2,000 unemployed benefit recipients received €560/month, designed to reduce welfare-trap effects and simplify the interface with work.
The results sharpened the real administrative puzzle:
employment effects were modest,
but wellbeing, perceived security, and trust indicators improved.
That split is analytically productive: it exposes the challenge of turning learning into reform when political justifications, performance metrics, and administrative routines are tuned to something else (employment). Finland shows what experimentation looks like when capacity is strong—and still adjusting priorities and reconfiguring delivery steps are politically and organisationally hard.
Kenya: experimentation enabled by digital rails and external actors
GiveDirectly’s long-horizon UBI experiment (2018–present) covers 14,474 households across 295 villages, using M-PESA, multiple treatment arms (long-term monthly, short-term monthly, lump sum), and long-duration follow-up.
During COVID-19, transfers improved wellbeing measures (hunger, sickness, depression), but the case surfaces the boundary question: whose capability is being built?
Because the programme is NGO-led, it can generate high-quality evidence without necessarily strengthening the state’s own structural capacity—registries, grievance routines, fiscal commitment, democratic legitimacy, service integration.
Kenya therefore dramatises the distinction between:
experimentation as parallel delivery and learning, and
experimentation as state-owned capability-building.
The Week 7 takeaway
Dynamic capabilities rarely arrive as “dynamic capabilities.”
They arrive as institutional hacks—missions, labs, prizes, sandboxes, RCT units, experimentalist governance arrangements—because these forms create enough legitimacy to do work that the core organisation cannot yet do safely.
But those forms only matter if they change the organisation’s repeatable machinery: mandates, budget routines, procurement patterns, HR rules, decision gates, performance measures, and leadership forums.
Three questions to take into practice
When you encounter “innovation” in government this week—an RCT team, a mission unit, a lab, a prize—try these:
Which dynamic capability is this really trying to build? (sensing, reprioritising, coalition-building, learning, reconfiguring delivery)
What is the protective shell protecting against? (blame risk, mandate limits, procurement rigidity, ethics concerns, political conflict)
Where is the “scale/stop/institutionalise” gate—and who has authority to use it?
If you can answer those three, you’re no longer just admiring innovation theatre—you’re diagnosing capability-building.